The Problem of Agreement in Distributed Systems
A global payment system needed to process transactions across multiple data centers.
If one data center received a transaction update, others needed to sync. But how could they agree on the correct data while avoiding conflicts?
The solution? Consensus algorithms—ensuring all nodes in a distributed system agree on the same state, even with failures.
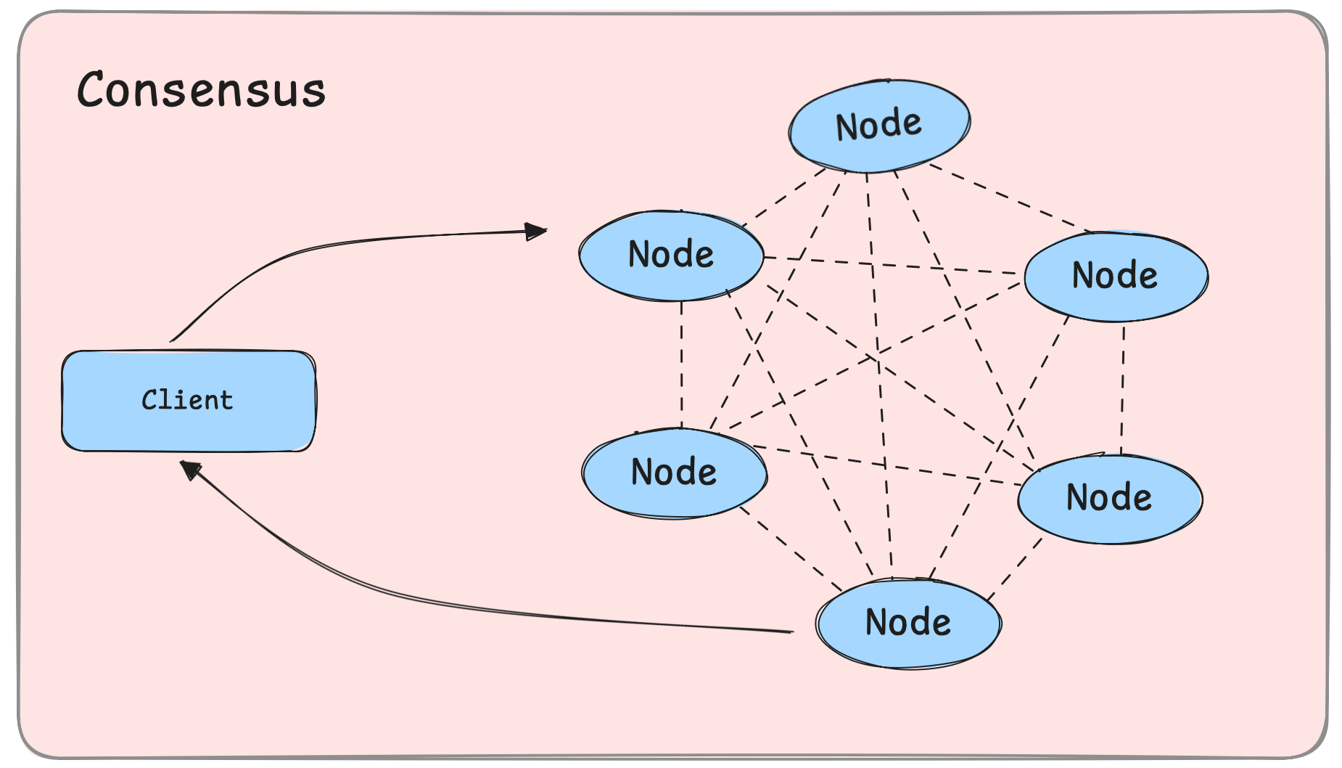
What is Consensus in Distributed Systems?
Consensus is the process by which multiple nodes in a distributed system agree on a single version of the truth.
Example: A banking system must ensure account balances remain consistent across all replicas, even if some servers fail.
Challenges:
Network failures may delay updates.
Nodes may crash or send conflicting data.
Systems must handle failures while maintaining accuracy.
Popular Consensus Algorithms
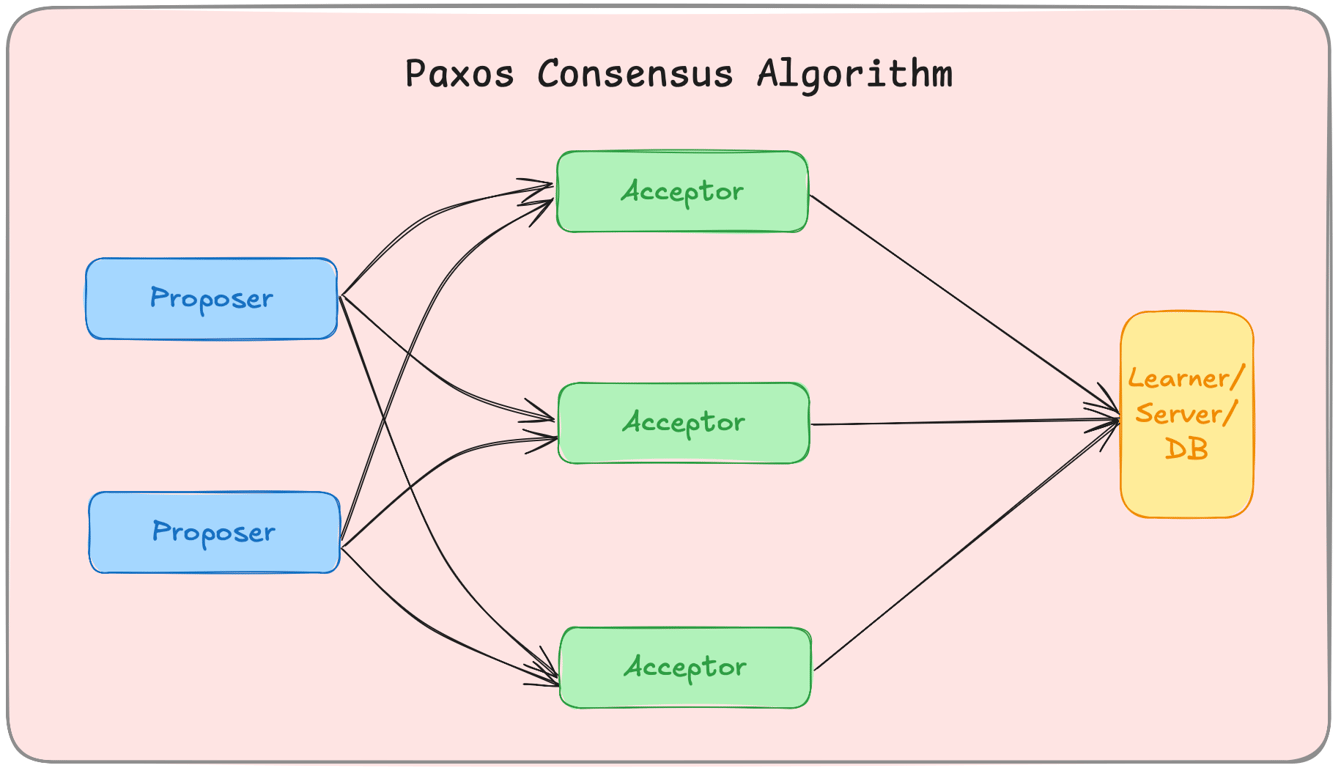
1. Paxos – The Gold Standard for Distributed Consensus
Paxos ensures fault-tolerant agreement in a distributed system, even if some nodes fail.
How It Works:A proposer suggests a value.
Acceptors vote on the value.
Once a majority agrees, the value is committed.
✔ Pros: Handles network failures efficiently. ✖ Cons: Complex to implement.
Example: Google Spanner uses Paxos for distributed transactions.
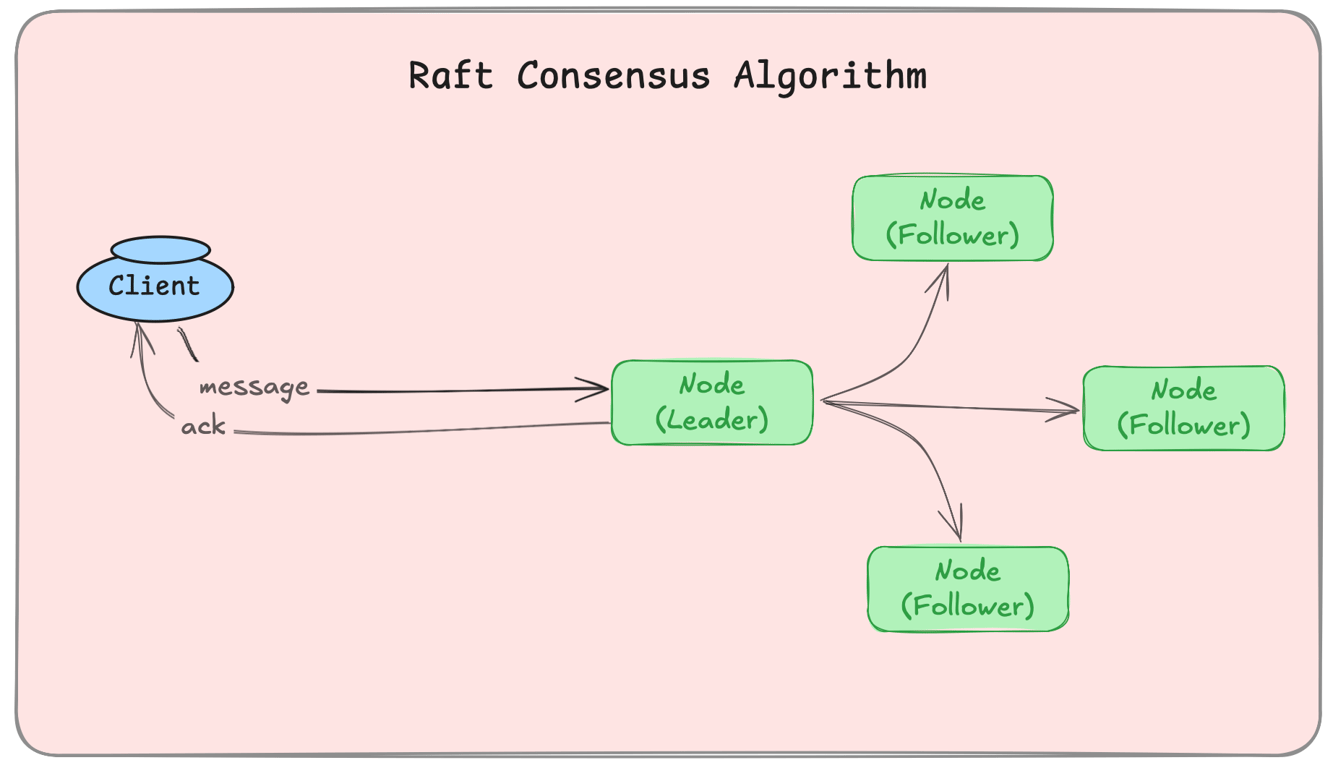
2. Raft – A Simpler Alternative to Paxos
Raft is an easier-to-understand consensus algorithm used in distributed databases.
How It Works:A leader node is elected.
The leader logs updates and replicates them to followers.
If the leader fails, a new leader is elected.
✔ Pros: Simpler and more understandable than Paxos. ✖ Cons: Leader election may slow down processing.
Example: Kubernetes uses Raft for cluster state management.
3. Two-Phase Commit (2PC) – Strong Consistency for Transactions
2PC ensures a distributed transaction is either fully committed or fully aborted.
How It Works:Prepare Phase – The coordinator asks all participants if they can commit.
Commit Phase – If all agree, the transaction is finalized.
✔ Pros: Ensures strong consistency. ✖ Cons: Slower and vulnerable to coordinator failure.
Example: Distributed databases use 2PC to ensure ACID-compliant transactions.
4. Gossip Protocol – Decentralized Information Sharing
Gossip Protocol spreads information in a peer-to-peer fashion, similar to how rumors spread in real life.
How It Works:A node shares data with a few random peers.
Peers spread the update further, eventually reaching all nodes.
✔ Pros: Scales well for large networks. ✖ Cons: Can result in delayed updates.
Example: Amazon DynamoDB uses Gossip Protocol for node coordination.
Choosing the Right Consensus Algorithm
Use Case
Best Algorithm
Distributed databases
Paxos, Raft
Leader election
Raft
ACID transactions
2PC
Large-scale, decentralized networks
Gossip Protocol
Real-World Use Cases
1. Google Spanner (Paxos for Global Transactions)
Ensures strong consistency across data centers.
2. Kubernetes (Raft for Cluster Management)
Maintains consistent cluster state.
3. Amazon DynamoDB (Gossip Protocol for Scalability)
Distributes data updates efficiently across nodes.
Conclusion
Consensus algorithms enable distributed systems to function reliably.
Paxos is robust but complex.
Raft simplifies leader election and replication.
2PC ensures transaction consistency.
Gossip Protocol scales decentralized updates efficiently.
Next, we’ll explore Circuit Breaker, Bulkheading & Resilient Systems – Netflix Hystrix, Resilience4J.


